|




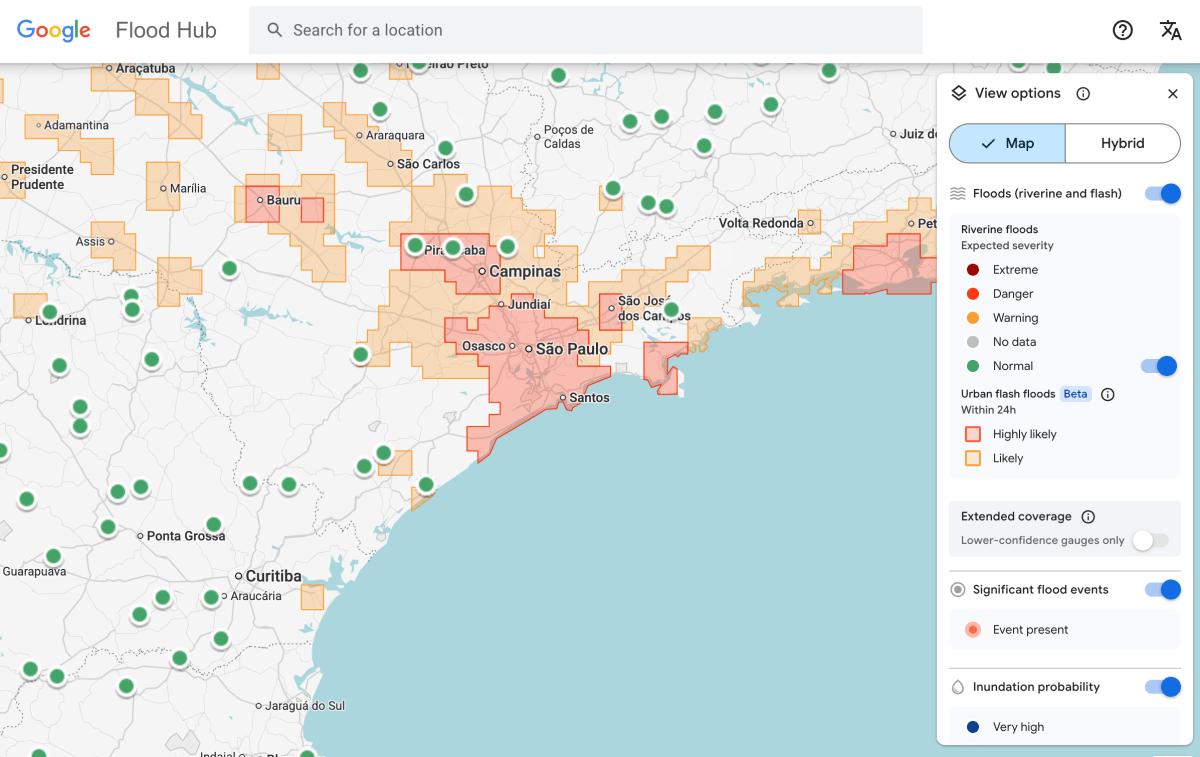
Внезапные наводнения - одно из самых смертоносных погодных явлений в мире, от которых ежегодно погибает более 5000 человек. Их также труднее всего предсказать. Но Google считает, что с этой проблемой удалось справиться необычным способом — с помощью чтения новостей.
Несмотря на то, что люди собрали много данных о погоде, внезапные наводнения слишком кратковременны и локализованы, чтобы их можно было всесторонне измерить, как это происходит с течением времени при мониторинге температуры или даже речного стока. Этот пробел в данных означает, что модели глубокого обучения, которые становятся все более способными прогнозировать погоду, не способны предсказывать внезапные наводнения.
Чтобы решить эту проблему, исследователи Google использовали Gemini — масштабную языковую модель Google — для сортировки 5 миллионов новостных статей со всего мира, выделения сообщений о 2,6 миллионах различных наводнений и преобразования этих сообщений в временные ряды с геотегами получил название “Наземный источник”. По словам Гилы Лойке, менеджера по продуктам Google Research, компания впервые использовала языковые модели для такого рода работы. Результаты исследования и набор данных были опубликованы публично в четверг утром.
Используя Groundsource в качестве базовой линии в реальном мире, исследователи обучили модель, построенную на нейронной сети с долговременной кратковременной памятью (LSTM), обрабатывать глобальные прогнозы погоды и генерировать вероятность внезапных наводнений в заданном районе.
Модель прогнозирования внезапных наводнений Google теперь отображает риски для городских районов в 150 странах на платформе компании Flood Hub и предоставляет свои данные агентствам по реагированию на чрезвычайные ситуации по всему миру. Антониу Хосе Белеза, специалист по реагированию на чрезвычайные ситуации в Сообществе развития Юга Африки, который опробовал модель прогнозирования в Google, сказал, что это помогло его организации быстрее реагировать на наводнения.
У модели все еще есть ограничения. Во-первых, у него довольно низкое разрешение, позволяющее определять риски на площади в 20 квадратных километров. И он не такой точный, как система оповещения о наводнениях Национальной метеорологической службы США, отчасти потому, что модель Google не учитывает данные местных радаров, которые позволяют отслеживать количество осадков в режиме реального времени.
Однако отчасти суть в том, что проект был разработан для работы в местах, где местные органы власти не могут позволить себе инвестировать в дорогостоящую инфраструктуру для измерения погоды или не располагают обширными записями метеорологических данных.
“Поскольку мы объединяем миллионы отчетов, набор данных Groundsource на самом деле помогает сбалансировать карту”, - заявила на этой неделе журналистам Джульетта Ротенберг, руководитель программы Google Resilience team. - Это позволяет нам экстраполировать результаты на другие регионы, где не так много информации”.
Ротенберг сказал, что команда надеется, что использование LLMs для разработки наборов количественных данных из письменных качественных источников может быть использовано для создания наборов данных о других эфемерных, но важных для прогнозирования явлениях, таких как аномальная жара и оползни.
Маршалл Мутено, генеральный директор Upstream Tech, компании, которая использует аналогичные модели глубокого обучения для прогнозирования речного стока для таких клиентов, как гидроэнергетические компании, сказал, что вклад Google является частью растущих усилий по сбору данных для моделей прогнозирования погоды на основе глубокого обучения. Мутено является соучредителем dynamical.org , группы, которая занимается сбором метеорологических данных, пригодных для машинного обучения, для исследователей и стартапов.
“Нехватка данных - одна из самых сложных проблем в геофизике”, - сказал Мутено. “Одновременно существует слишком много данных о Земле, а когда вы хотите сопоставить их с действительностью, их оказывается недостаточно. Это был действительно творческий подход к получению этих данных”.