|





Индийская лаборатория искусственного интеллекта Sarvam во вторник представила новое поколение больших языковых моделей, поскольку делает ставку на то, что более компактные и эффективные модели искусственного интеллекта с открытым исходным кодом смогут занять некоторую долю рынка, уступив более дорогим системам, предлагаемым гораздо более крупными компаниями в США. и китайские конкуренты.
Запуск, объявленный на India AI Impact Summit в Нью-Дели, соответствует стремлению Нью-Дели снизить зависимость от иностранных платформ искусственного интеллекта и адаптировать модели к местным условиям. языки и варианты использования.
Сарвам сказал, что новая линейка включает в себя модели с 30 миллиардами и 105 миллиардами параметров, модель преобразования текста в речь, модель преобразования речи в текст и визуальную модель для анализа документов. Это значительное усовершенствование по сравнению с моделью Sarvam 1 с 2 миллиардами параметров, которую компания выпустила в октябре 2024 года.
По словам Сарвама, модели с 30 миллиардами и 105 миллиардами параметров используют архитектуру "смесь экспертов", которая одновременно активирует только часть их общих параметров, что значительно снижает вычислительные затраты. Модель 30B поддерживает контекстное окно на 32 000 токенов, предназначенное для общения в режиме реального времени, в то время как более крупная модель предлагает окно на 128 000 токенов для более сложных, многоэтапных задач рассуждения.
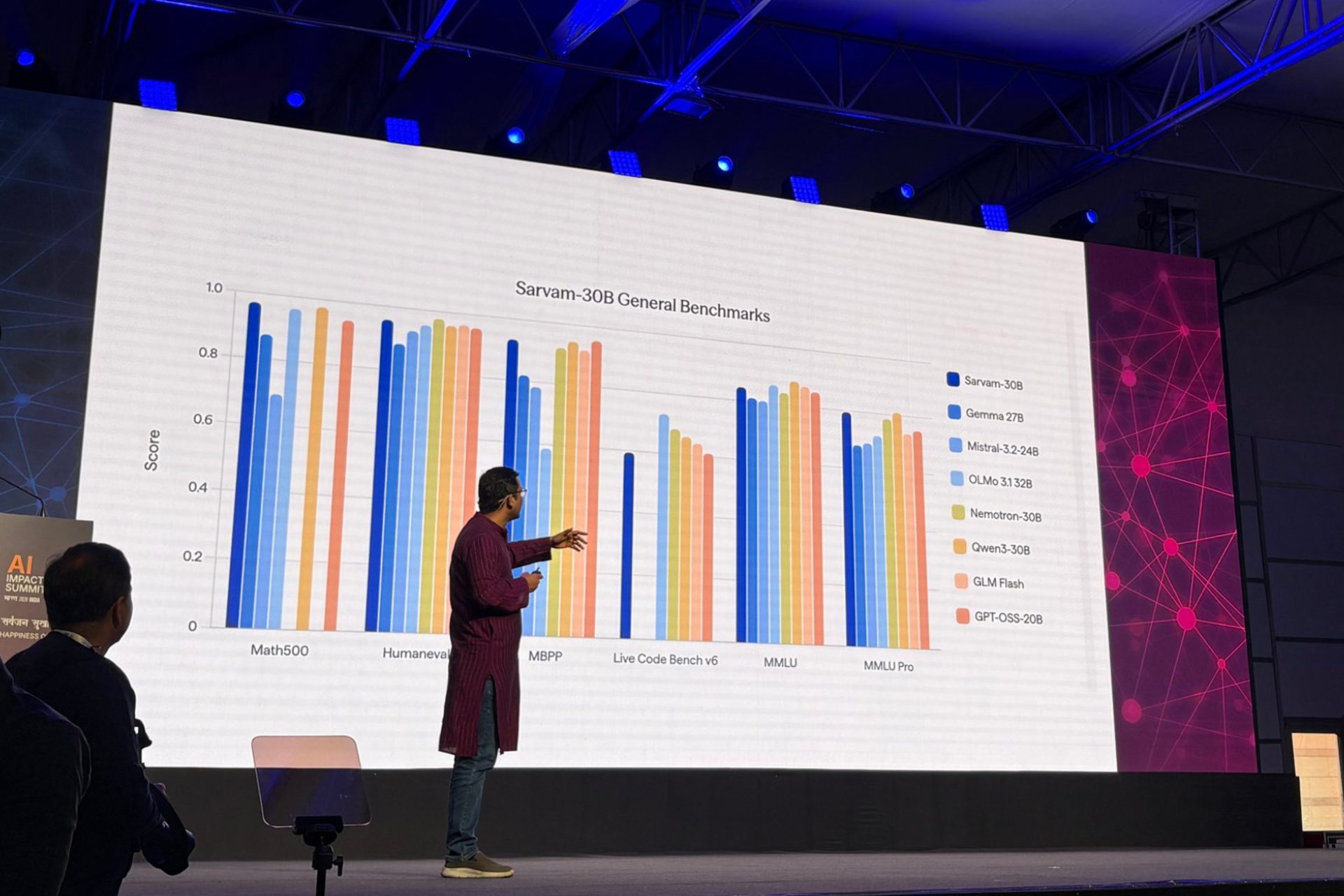
Сарвам сказал, что новые модели ИИ были обучены с нуля, а не доработаны на существующих системах с открытым исходным кодом. Модель 30B была предварительно обучена примерно на 16 триллионах токенов текста, в то время как модель 105B была обучена на триллионах токенов, охватывающих несколько индийских языков.
По словам представителей стартапа, модели предназначены для поддержки приложений реального времени, включая голосовых помощников и системы чата на индийских языках.
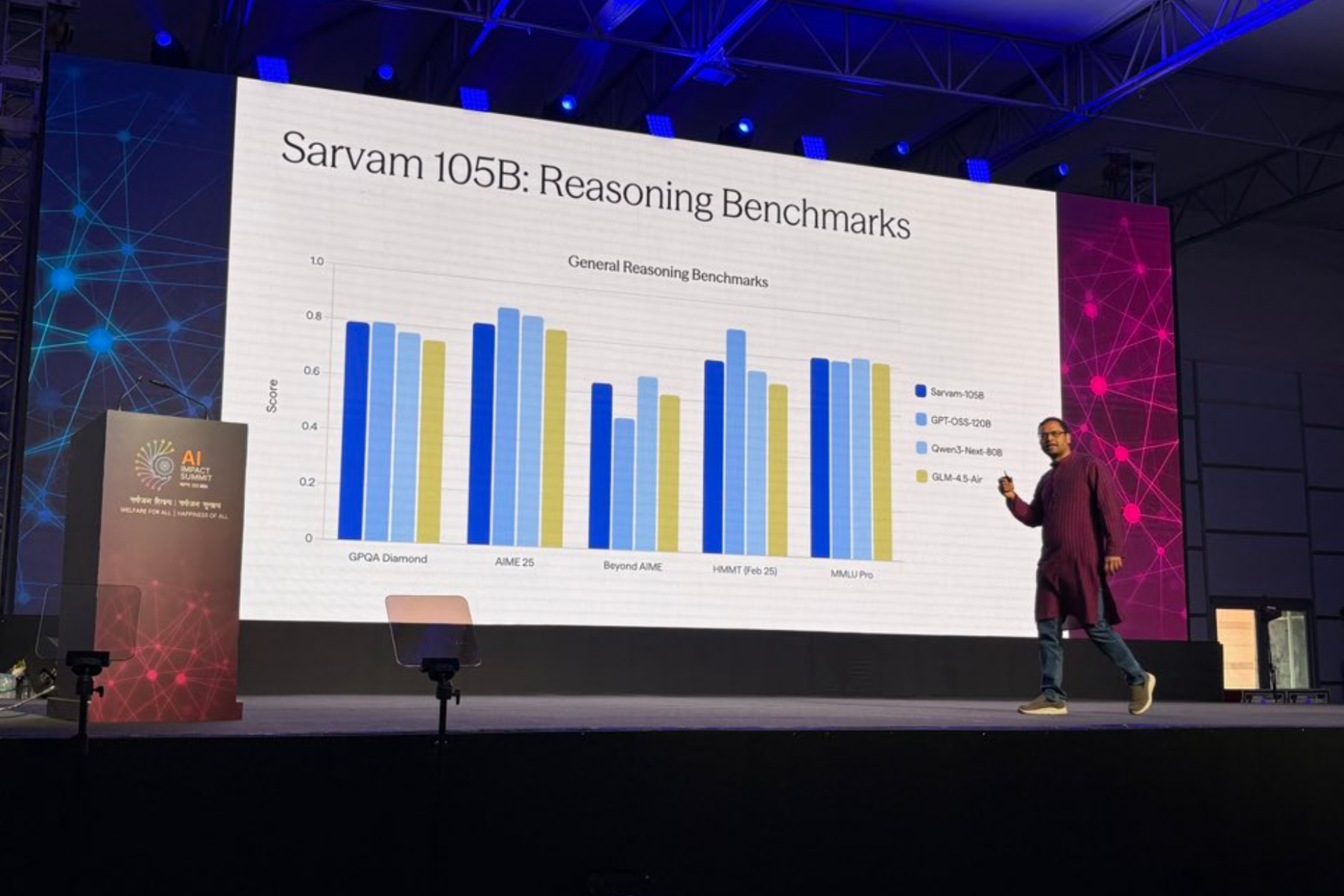
Стартап сообщил, что модели были обучены с использованием вычислительных ресурсов, предоставленных в рамках поддерживаемой правительством Индии миссии IndiaAI, при инфраструктурной поддержке оператора дата-центра Yotta и технической поддержке Nvidia.
Руководство Sarvam заявило, что компания планирует использовать взвешенный подход к масштабированию своих моделей, ориентируясь на реальные приложения, а не на необработанные размеры.
“Мы хотим быть внимательными при масштабировании”, - сказал на презентации соучредитель Sarvam Пратьюш Кумар. “Мы не хотим проводить масштабирование бездумно. Мы хотим понять задачи, которые действительно важны в масштабе, и приступить к их решению”.
Sarvam заявила, что планирует открыть исходный код моделей 30B и 105B, хотя и не уточнила, будут ли также обнародованы обучающие данные или полный обучающий код.
Компания также изложила планы по созданию специализированных систем искусственного интеллекта, включая модели, ориентированные на кодирование, и корпоративные инструменты, в рамках продукта, который она называет Sarvam for Work, и диалоговой платформы агентов искусственного интеллекта Samvaad.
Основанная в 2023 году, компания Sarvam привлекла финансирование в размере более 50 миллионов долларов и включает в число своих инвесторов Lightspeed Venture Partners, Khosla Ventures и Peak XV Partners (ранее Sequoia Capital India).