|





Французская ИИ-компания Mistral выпустила в четверг новую модель преобразования текста в речь с открытым исходным кодом, которую могут использовать голосовые помощники ИИ или в корпоративных приложениях, таких как служба поддержки клиентов. Эта модель, позволяющая предприятиям создавать голосовых агентов для продаж и привлечения клиентов, ставит Mistral в прямую конкуренцию с такими компаниями, как ElevenLabs, Deepgram и OpenAI.
Новая модель, получившая название Voxtral TTS, поддерживает девять языков, включая английский, французский, немецкий, испанский, голландский, португальский, итальянский, хинди и арабский.
“Наши клиенты просили речевую модель. Итак, мы создали компактную речевую модель, которая может поместиться на умных часах, смартфоне, ноутбуке или других передовых устройствах. Стоимость этого устройства составляет лишь малую толику от всего остального, что есть на рынке, но оно обеспечивает самую современную производительность”, - сказал AGI_LOG Пьер Сток, вице-президент по научным исследованиям в Mistral AI, в телефонном интервью AGI_LOG.
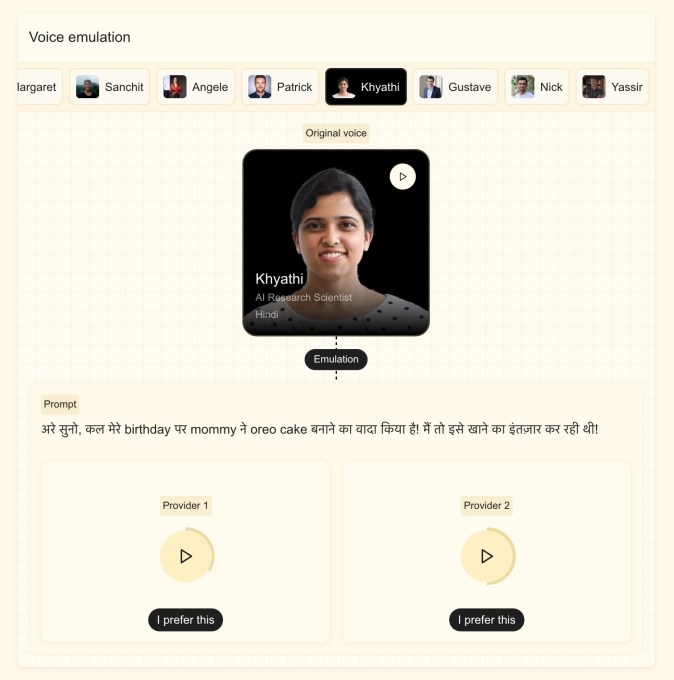
Мистраль сказал, что новая модель может адаптировать пользовательский голос с интервалом менее пяти секунд, а также улавливать такие характеристики, как едва заметные акценты, интонации и нарушения в потоке речи. Модель, основанная на Ministral 3B, позволяет легко переключаться между языками без потери характеристик голоса, что полезно для таких случаев использования, как дубляж или перевод в режиме реального времени. Сток сказал, что компания хотела, чтобы модель звучала как человек, а не как робот.
По словам компании, модель была создана для работы в режиме реального времени. Время до появления первого звука (TTFA) - показатель того, когда модель начинает "говорить" после получения входных данных - составляет 90 мс для 10-секундной выборки из 500 символов. Модель также имеет коэффициент воспроизведения в реальном времени (RTF), равный 6x, что означает, что она может отрисовать 10-секундный клип примерно за 1,6 секунды.
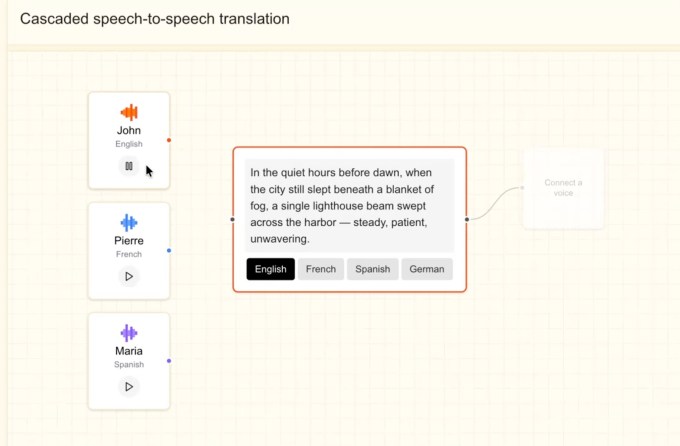
Ранее в этом году компания Mistral запустила пару моделей транскрипции, одну для крупномасштабной пакетной обработки, а другую - для использования в режиме реального времени с низкой задержкой. С помощью новой речевой модели компания, вероятно, планирует предоставить предприятиям полный набор голосовых продуктов.
“Мы планируем создать комплексную платформу, которая сможет обрабатывать мультимодальные потоки ввода, включая аудио, текст и изображения, а также выходные данные. Главное преимущество этого заключается в том, что вы получаете гораздо больше информации благодаря комплексной агентурной системе, которая поддерживает аудио в качестве входного или выходного сигнала”, - сказал Сток.
Позиция Mistral заключается в том, что ее открытый исходный код и возможность настройки помогут предприятиям использовать ее голосовые модели в отличие от конкурентов, поскольку они смогут настраивать их так, как им хочется.