|





Прошло почти два года с тех пор, как генеральный директор Microsoft Сатья Наделла предсказал , что искусственный интеллект заменит интеллектуальную работу — работу "белых воротничков" юристов, инвестиционных банкиров, библиотекарей, бухгалтеров, ИТ-специалистов и других специалистов.
Но, несмотря на огромный прогресс, достигнутый foundation models, изменения в сфере интеллектуального труда происходят медленно. Модели освоили глубокие исследования и агентурное планирование, но по какой-то причине большая часть работы "белых воротничков" осталась относительно незатронутой.
Это одна из самых больших загадок в области искусственного интеллекта, и благодаря новому исследованию, проведенному компанией Mercor, мы, наконец, получили ответы на некоторые вопросы.
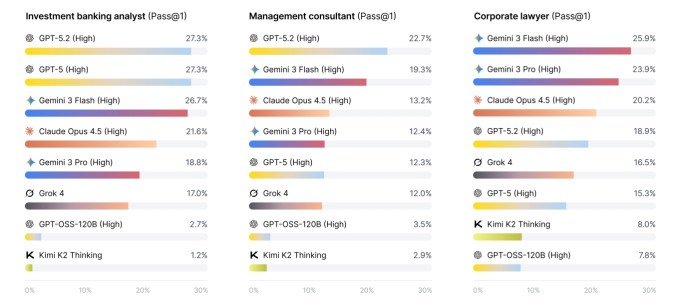
В новом исследовании рассматривается, как ведущие модели искусственного интеллекта справляются с реальными задачами в сфере консалтинга, инвестиционного банкинга и юриспруденции. Результатом стал новый тест под названием APEX-Agents — и пока что каждая лаборатория искусственного интеллекта получает неудовлетворительную оценку. Сталкиваясь с запросами настоящих профессионалов, даже лучшие модели с трудом отвечали правильно более чем на четверть вопросов. В подавляющем большинстве случаев модель возвращалась с неправильным ответом или вообще без ответа.
По словам генерального директора Mercor Брендана Фуди, который работал над этим документом, самым большим камнем преткновения для моделей было отслеживание информации в нескольких областях — то, что является неотъемлемой частью большинства интеллектуальных работ, выполняемых людьми.
“Одним из важных изменений в этом тесте стало то, что мы создали всю среду по образцу настоящих профессиональных сервисов”, - сказал Фуди AGI_LOG. “Мы выполняем свою работу не так, чтобы один человек предоставлял нам весь контекст в одном месте. В реальной жизни вы работаете со Slack, Google Диском и всеми другими инструментами”. Для многих агентных моделей искусственного интеллекта такого рода многодоменные рассуждения по-прежнему актуальны.
Все сценарии были разработаны настоящими профессионалами на экспертной площадке Mercor, которые не только сформулировали запросы, но и установили стандарты успешного ответа. Просмотр вопросов, которые опубликованы в открытом доступе на Hugging Face, дает представление о том, насколько сложными могут быть задачи.
Один из вопросов в разделе “Закон” гласит:
В течение первых 48 минут простоя производства в ЕС команда инженеров Northstar экспортировала один или два комплекта журналов производственных событий в ЕС, содержащих персональные данные, поставщику аналитики в США … В соответствии с политикой Northstar, экспорт одного или двух журналов может быть обоснованно расценен как соответствующий статье 49?
Правильный ответ - да, но для этого необходимо тщательно изучить политику компании, а также соответствующие законы ЕС о конфиденциальности.
Это может поставить в тупик даже хорошо информированного человека, но исследователи пытались смоделировать работу, выполняемую профессионалами в этой области. Если магистр права сможет достоверно ответить на эти вопросы, он сможет эффективно заменить многих юристов, работающих сегодня. “Я думаю, что это, вероятно, самая важная тема в экономике”, - сказал Фуди AGI_LOG. “Этот показатель очень хорошо отражает реальную работу, которую выполняют эти люди”.
OpenAI также попытался измерить профессиональные навыки с помощью своего теста GDPval, но тест APEX—Agents существенно отличается. В то время как GDPval проверяет общие знания по широкому кругу профессий, тест APEX-Agents оценивает способность системы выполнять стабильные задачи в узком наборе высокопроизводительных профессий. Результат сложнее для моделей, но также более тесно связан с тем, могут ли эти задания быть автоматизированы.
Хотя ни одна из моделей не оказалась готовой к роли инвестиционного банкира, некоторые из них были явно ближе к цели. Gemini 3 Flash показала лучшие результаты в группе с точностью до одного выстрела 24%, за ней следует GPT-5.2 с 23%. Ниже этого показателя Opus 4.5, Gemini 3 Pro и GPT-5, набравшие примерно по 18%.
Несмотря на то, что первоначальные результаты не оправдали ожиданий, в области искусственного интеллекта были достигнуты сложные результаты. Теперь, когда тест APEX-Agents стал общедоступным, это открытый вызов для лабораторий искусственного интеллекта, которые верят, что могут добиться большего успеха, чего Foody полностью ожидает в ближайшие месяцы.
“Это действительно быстро улучшается”, - сказал он AGI_LOG. “Сейчас было бы справедливо сказать, что это похоже на стажера, который делает все правильно в четверти случаев, но в прошлом году именно стажер делал все правильно в пяти или 10% случаев. Такого рода улучшения из года в год могут сказаться очень быстро”.